



Recent Projects
Prof. Antoni CHAN
On Diversity in Image Captioning: Metrics and Methods |
|
|
|
|
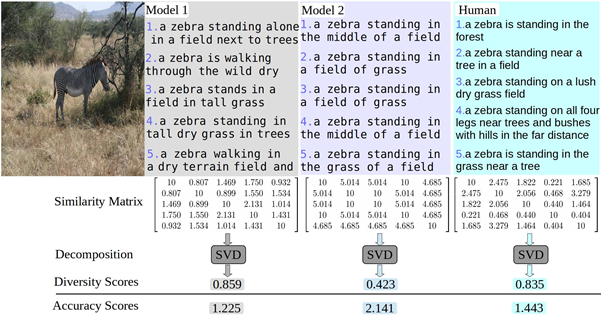
In this project, we focus on the diversity of image captions. First, diversity metrics are proposed which is more correlated to human judgment. Second, we re-evaluate the existing models and find that (1) there is a large gap between human and the existing models in the diversity-accuracy space, (2) using reinforcement learning (CIDEr reward) to train captioning models leads to improving accuracy but reduce diversity. Third, we propose a simple but efficient approach to balance diversity and accuracy via reinforcement learning—using the linear combination of cross-entropy and CIDEr reward. |
|
Wide-Area Crowd Counting via Ground-Plane Density Maps and Multi-View Fusion CNNs |
|

|
|
|
Crowd counting in single-view images has achieved outstanding performance on existing counting datasets. However, single-view counting is not applicable to large and wide scenes (e.g., public parks, long subway platforms, or event spaces) because a single camera cannot capture the whole scene in adequate detail for counting, e.g., when the scene is too large to fit into the field-of-view of the camera, too long so that the resolution is too low on faraway crowds, or when there are too many large objects that occlude large portions of the crowd. Therefore, to solve the wide-area counting task requires multiple cameras with overlapping fields-of-view. In this propose, we propose a deep neural network framework for multi-view crowd counting, which fuses information from multiple camera views to predict a scene-level crowd density map on the ground-plane of the 3D world. |
|
Learning Dynamic Memory Networks for Object Tracking |
|

|
|
|
Template-matching methods for visual tracking have gained popularity recently due to their good performance and fast speed. However, they lack effective ways to adapt to changes in the target object’s appearance, making their tracking accuracy still far from state-of-the-art. In this project, we propose a dynamic memory network to adapt the template to the target’s appearance variations during tracking. The reading and writing process of the external memory is controlled by an LSTM network with the search feature map as input. A spatial attention mechanism is applied to concentrate the LSTM input on the potential target as the location of the target is at first unknown. To prevent aggressive model adaptivity, we apply gated residual template learning to control the amount of retrieved memory that is used to combine with the initial template. In order to alleviate the drift problem, we also design a “negative” memory unit that stores templates for distractors, which are used to cancel out wrong responses from the object template. To further boost the tracking performance, an auxiliary classification loss is added after the feature extractor part. Unlike tracking-by-detection methods where the object’s information is maintained by the weight parameters of neural networks, which requires expensive online fine-tuning to be adaptable, our tracker runs completely feed-forward and adapts to the target’s appearance changes by updating the external memory. Moreover, the capacity of our model is not determined by the network size as with other trackers – the capacity can be easily enlarged as the memory requirements of a task increase, which is favorable for memorizing long-term object information. |
|
